💰 Festlegen von Team-Budgets
Ausgaben nachverfolgen, Budgets für Ihr internes Team festlegen
Monatliche Team-Budgets festlegen
1. Ein Team erstellen
max_budget=000000001festlegen (maximaler Betrag, den das Team ausgeben darf)budget_duration="1d"festlegen (wie oft das Budget aktualisiert werden soll)
- API
- Admin UI
Ein neues Team erstellen und max_budget und budget_duration festlegen
curl -X POST 'http://0.0.0.0:4000/team/new' \
-H 'Authorization: Bearer sk-1234' \
-H 'Content-Type: application/json' \
-d '{
"team_alias": "QA Prod Bot",
"max_budget": 0.000000001,
"budget_duration": "1d"
}'
Antwort
{
"team_alias": "QA Prod Bot",
"team_id": "de35b29e-6ca8-4f47-b804-2b79d07aa99a",
"max_budget": 0.0001,
"budget_duration": "1d",
"budget_reset_at": "2024-06-14T22:48:36.594000Z"
}

Mögliche Werte für budget_duration
budget_duration | Wann das Budget zurückgesetzt wird |
|---|---|
budget_duration="1s" | alle 1 Sekunde |
budget_duration="1m" | jede 1 Minute |
budget_duration="1h" | jede 1 Stunde |
budget_duration="1d" | jeden 1 Tag |
budget_duration="30d" | jeden 1 Monat |
2. Einen Schlüssel für das Team erstellen
Erstellen Sie einen Schlüssel für Team=QA Prod Bot und team_id="de35b29e-6ca8-4f47-b804-2b79d07aa99a" aus Schritt 1
- API
- Admin UI
💡 Das Budget für Team="QA Prod Bot" gilt für dieses Team
curl -X POST 'http://0.0.0.0:4000/key/generate' \
-H 'Authorization: Bearer sk-1234' \
-H 'Content-Type: application/json' \
-d '{"team_id": "de35b29e-6ca8-4f47-b804-2b79d07aa99a"}'
Antwort
{"team_id":"de35b29e-6ca8-4f47-b804-2b79d07aa99a", "key":"sk-5qtncoYjzRcxMM4bDRktNQ"}

3. Testen
Verwenden Sie den Schlüssel aus Schritt 2 und führen Sie diese Anfrage zweimal aus
- API
- Admin UI
curl -X POST 'http://0.0.0.0:4000/chat/completions' \
-H 'Authorization: Bearer sk-mso-JSykEGri86KyOvgxBw' \
-H 'Content-Type: application/json' \
-d ' {
"model": "llama3",
"messages": [
{
"role": "user",
"content": "hi"
}
]
}'
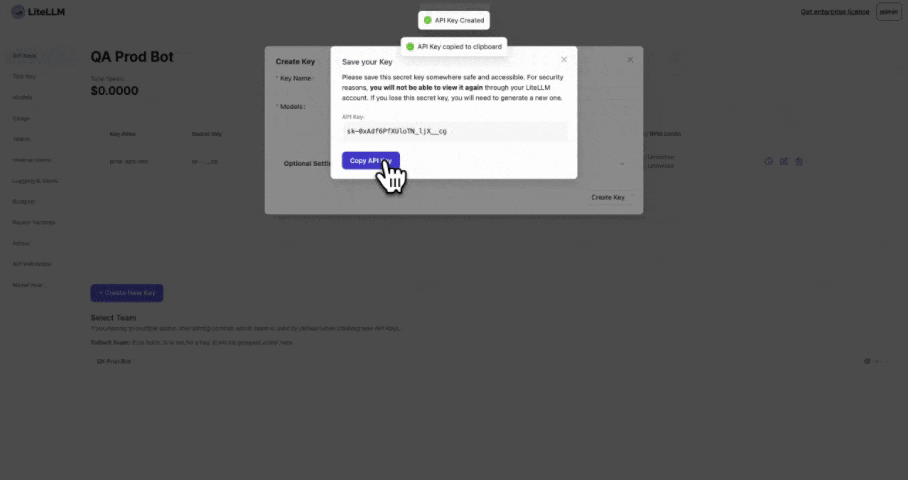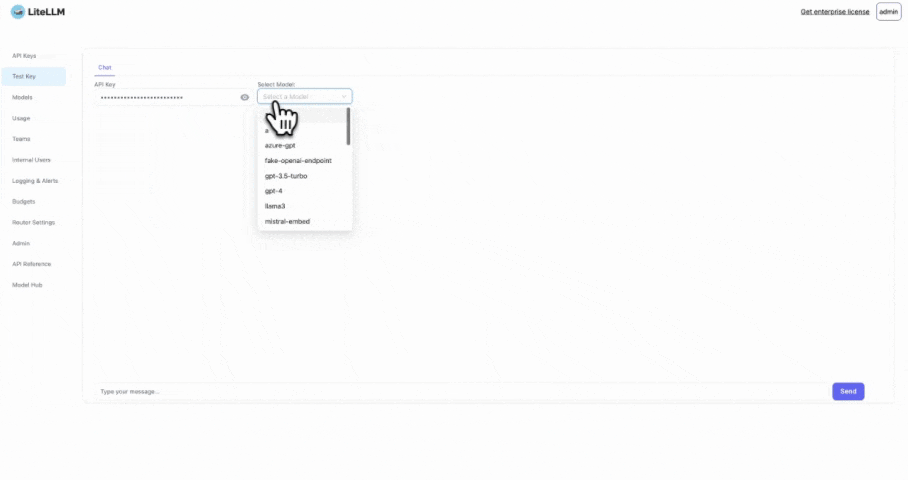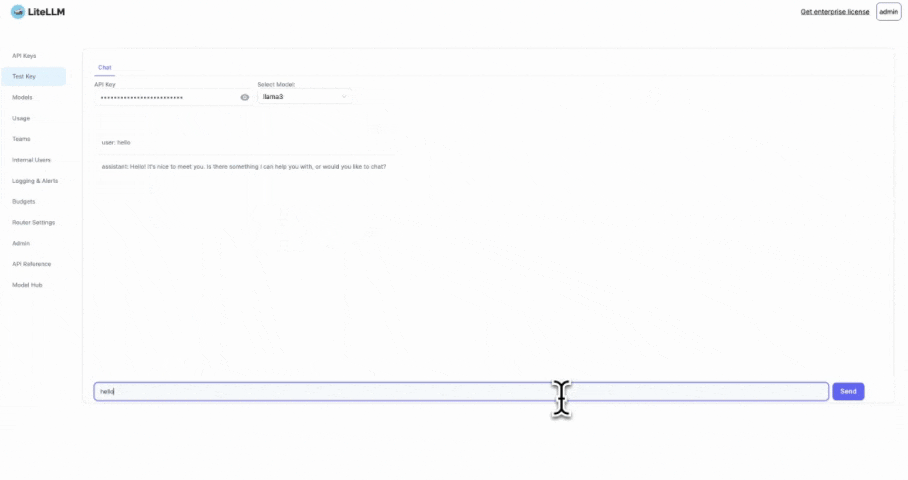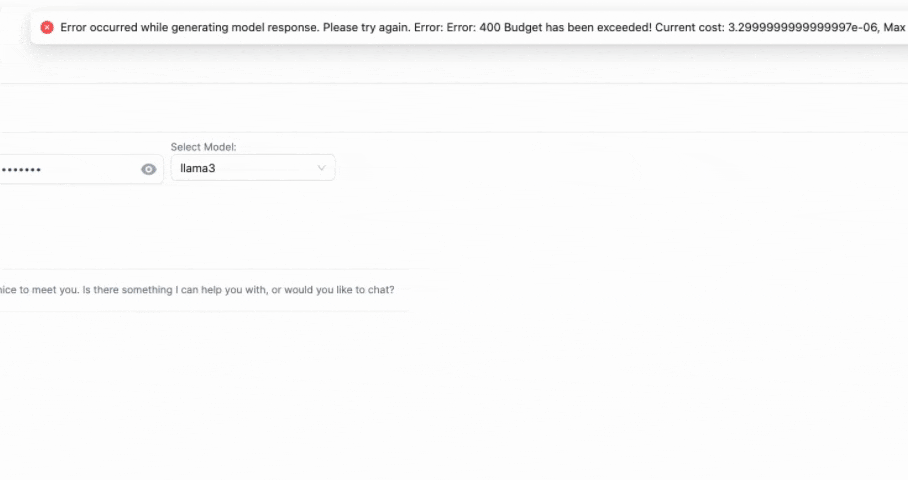
Bei der 2. Antwort erwarten Sie die folgende Ausnahme
{
"error": {
"message": "Budget has been exceeded! Current cost: 3.5e-06, Max budget: 1e-09",
"type": "auth_error",
"param": null,
"code": 400
}
}
Erweitert
Prometheus-Metriken für remaining_budget
Weitere Informationen zu Prometheus-Metriken finden Sie hier
Sie benötigen Folgendes in Ihrer Proxy-Konfigurationsdatei config.yaml:
litellm_settings:
success_callback: ["prometheus"]
failure_callback: ["prometheus"]
Erwarten Sie, diese Metrik in Prometheus zu sehen, um das verbleibende Budget für das Team zu verfolgen
litellm_remaining_team_budget_metric{team_alias="QA Prod Bot",team_id="de35b29e-6ca8-4f47-b804-2b79d07aa99a"} 9.699999999999992e-06
Dynamische TPM/RPM-Zuweisung
Verhindern Sie, dass Projekte zu viel TPM/RPM verbrauchen.
Weisen Sie TPM/RPM-Kontingente dynamisch API-Schlüsseln zu, basierend auf aktiven Schlüsseln in dieser Minute. Code anzeigen
- Konfigurieren Sie config.yaml
model_list:
- model_name: my-fake-model
litellm_params:
model: gpt-3.5-turbo
api_key: my-fake-key
mock_response: hello-world
tpm: 60
litellm_settings:
callbacks: ["dynamic_rate_limiter"]
general_settings:
master_key: sk-1234 # OR set `LITELLM_MASTER_KEY=".."` in your .env
database_url: postgres://.. # OR set `DATABASE_URL=".."` in your .env
- Proxy starten
litellm --config /path/to/config.yaml
- Testen Sie es!
"""
- Run 2 concurrent teams calling same model
- model has 60 TPM
- Mock response returns 30 total tokens / request
- Each team will only be able to make 1 request per minute
"""
import requests
from openai import OpenAI, RateLimitError
def create_key(api_key: str, base_url: str):
response = requests.post(
url="{}/key/generate".format(base_url),
json={},
headers={
"Authorization": "Bearer {}".format(api_key)
}
)
_response = response.json()
return _response["key"]
key_1 = create_key(api_key="sk-1234", base_url="http://0.0.0.0:4000")
key_2 = create_key(api_key="sk-1234", base_url="http://0.0.0.0:4000")
# call proxy with key 1 - works
openai_client_1 = OpenAI(api_key=key_1, base_url="http://0.0.0.0:4000")
response = openai_client_1.chat.completions.with_raw_response.create(
model="my-fake-model", messages=[{"role": "user", "content": "Hello world!"}],
)
print("Headers for call 1 - {}".format(response.headers))
_response = response.parse()
print("Total tokens for call - {}".format(_response.usage.total_tokens))
# call proxy with key 2 - works
openai_client_2 = OpenAI(api_key=key_2, base_url="http://0.0.0.0:4000")
response = openai_client_2.chat.completions.with_raw_response.create(
model="my-fake-model", messages=[{"role": "user", "content": "Hello world!"}],
)
print("Headers for call 2 - {}".format(response.headers))
_response = response.parse()
print("Total tokens for call - {}".format(_response.usage.total_tokens))
# call proxy with key 2 - fails
try:
openai_client_2.chat.completions.with_raw_response.create(model="my-fake-model", messages=[{"role": "user", "content": "Hey, how's it going?"}])
raise Exception("This should have failed!")
except RateLimitError as e:
print("This was rate limited b/c - {}".format(str(e)))
Erwartete Antwort
This was rate limited b/c - Error code: 429 - {'error': {'message': {'error': 'Key=<hashed_token> over available TPM=0. Model TPM=0, Active keys=2'}, 'type': 'None', 'param': 'None', 'code': 429}}
✨[BETA]Priorität festlegen / Kontingent reservieren
Reservieren Sie TPM/RPM-Kapazität für Projekte in der Produktion.
Die Reservierung von TPM/RPM auf Schlüsseln basierend auf der Priorität ist eine Premium-Funktion. Bitte erwerben Sie eine Enterprise-Lizenz dafür.
- Konfigurieren Sie config.yaml
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: "gpt-3.5-turbo"
api_key: os.environ/OPENAI_API_KEY
rpm: 100
litellm_settings:
callbacks: ["dynamic_rate_limiter"]
priority_reservation: {"dev": 0, "prod": 1}
general_settings:
master_key: sk-1234 # OR set `LITELLM_MASTER_KEY=".."` in your .env
database_url: postgres://.. # OR set `DATABASE_URL=".."` in your .env
priority_reservation
- Dict[str, float]
- str: kann ein beliebiger String sein
- float: von 0 bis 1. Geben Sie den Prozentsatz der TPM/RPM an, der für Schlüssel dieser Priorität reserviert werden soll.
Proxy starten
litellm --config /path/to/config.yaml
- Erstellen Sie einen Schlüssel mit dieser Priorität
curl -X POST 'http://0.0.0.0:4000/key/generate' \
-H 'Authorization: Bearer <your-master-key>' \
-H 'Content-Type: application/json' \
-D '{
"metadata": {"priority": "dev"} # 👈 KEY CHANGE
}'
Erwartete Antwort
{
...
"key": "sk-.."
}
- Testen Sie es!
curl -X POST 'http://0.0.0.0:4000/chat/completions' \
-H 'Content-Type: application/json' \
-H 'Authorization: sk-...' \ # 👈 key from step 2.
-D '{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
}'
Erwartete Antwort
Key=... over available RPM=0. Model RPM=100, Active keys=None